
Introduction
In recent years, the spotlight on artificial intelligence has increasingly focussed on the advances and applications of generative AI and large language models (LLM). LLMs’ ability to understand, generate, and manipulate human-like text has garnered huge interest, as well as some concern. This has also led to the rapid adoption of this new technology across a huge range of applications. One notable example of this is in Health Tech, where LLMs have been posited as a solution in a wide range of areas – from clinical decision support systems to virtual health assistants. The increasing number of commercial applications of LLMs in healthcare has been mirrored in rapidly growing patent filings in this area.
In the midst of this activity and media interest it is easy to forget that the commercial application of LLMs is still at a very early stage, with the landmark paper proposing the architecture on which the models are built only being published in late 2017. For this reason, there is very little precedent setting the approach of the patent office in deciding questions of patentability. However, there are several existing aspects of UK and European law that are crucial to understand to navigate the challenges of patenting applications of LLMs.
Having worked on applications involving the use of LLMs in a range of medical and health applications for clients, in this article we summarise the developing approach of the UK and European patent offices in assessing these technologies, and provide guidance for innovators in this challenging area.
What is an LLM?
To better understand some of the patentability challenges it is useful to understand some of the fundamental principles of how an LLM operates. Like most machine learning based NLP methods, LLMs convert natural language to tokens (i.e. vectors) representing individual words or sub-word text fragments on which a mathematical model can operate. It is somewhat reassuring that, despite some understandable concern about the apparently human-like intelligence of these models, fundamentally, each word that is output is just the result of a simple calculation of probability across all possible words (represented by respective tokens) in the model’s vocabulary. This process is repeated to generate a sequence of output words, whereby an input sequence of tokens is provided to the model, which is then processed and converted to an output sequence of representations that are used to calculate the probabilities for an output sequence of tokens.
The fundamental advance of the Transformer model, underpinning all LLMs, was the application of a concept called “attention”. Previously NLP models had generally operated by processing a string of text sequentially, but the key advance of this paper was to allow the model to consider the full input sequence at once and learn which parts of the input text are more predictive of the correct output token.
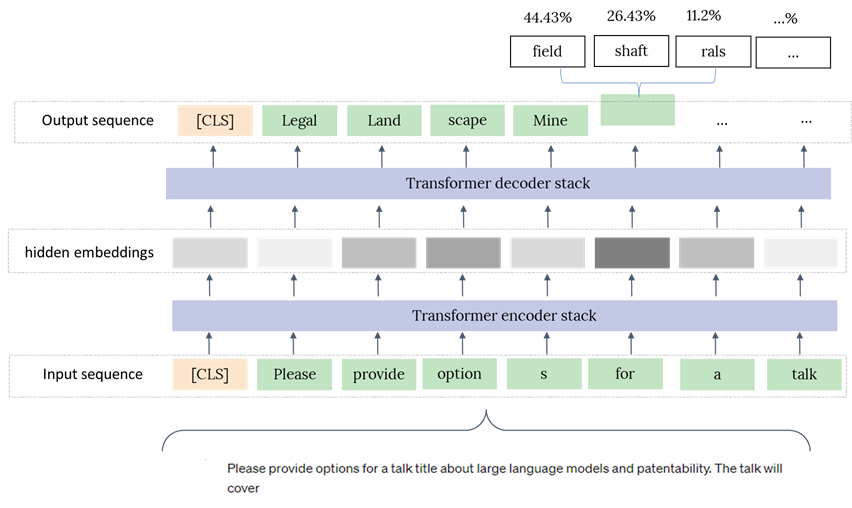
Another key advantage of these models is that they could be trained on huge text data sets, in an unsupervised manner, by taking sentences from the data set (e.g. text data on the internet), masking a word in the input sequence and training the model to learn to predict the masked word. By training a model on this masked language modelling objective, the model can reason over these vast data sets to learn patterns in the use of text in order to understand which parts of an input text string to focus on to recognise a masked word. This pre-training objective is used in the vast majority of pre-trained language models – providing a generic model that has general understanding of the context of language in the training data set.
Many applications of LLMs use a two-stage training process in which first a model is pre-trained on vast general test datasets using this kind of unsupervised training objective, before applying a task-specific or fine-tuning training objective for a particular application. Examples of the latter could include training the model on a clinical question-answer task using a specific dataset of questions and answers.
Many commercial applications of LLMs use this type of process: starting from an available pre-trained model and applying specific fine-tuning steps for a particular application. One sector in which we have seen an increasing number of applications of LLMs is in medical and health technologies. These include clinical assistants trained to assist with clinical decision making, such as triage, and diagnosis; AI-powered medical scribes that can generate, summarise and structure clinical notes; diagnosis of neurological conditions by processing input speech; and the application of LLM-based approaches for drug discovery, by making predictions based on biomedical literature and other data sources.
The growth in commercial applications of LLMs in health and medicine has been reflected in an increasing number of patent filings. However, this is an area which is challenging to obtain protection of in the UK and Europe.
Patentability challenges
Despite longstanding misconceptions about the patentability of software inventions, it is possible to obtain patent protection for AI technologies – in fact it is becoming increasingly routine with rapidly increasing numbers of patents granted each year. Although the UK and European patent offices each use a slightly different framework for assessing patent eligibility, a general, shared principle is that if a novel LLM or other form of AI-based technology is used to solve a problem in a field that is considered “technical”, i.e. not falling solely in one of the excluded fields, it will avoid the exclusions and meet the patent eligibility requirements.
Positively for Health Tech innovators, the application of AI to solving problems in healthcare is looked on favourably. The EPO cites several patent-eligible applications of AI, including providing a medical diagnosis by an automated system processing physiological measurements. In contrast, a claim to an LLM applied to a solely administrative or business task will not be considered patent eligible.
A particular challenge for LLM innovation is that both the UK and European patent offices usually consider applications relating purely to the analysis or classification of text data to fall within the non-technical domain. Given that LLMs involve processing a text input to provide an output, often in the form of text itself, this can present a challenge to patent protection. It is therefore essential, at the drafting stage, to frame the invention properly to demonstrate its utility in a technical field, even if it also solves problems in a non-technical field. This may mean emphasising the applications or advantages of the technology that the inventors themselves may not consider primary.
Applications of LLMs and patentability
Example 1: Automated assessment of speech to diagnose cognitive conditions
One of our clients has developed novel LLM-based techniques for processing speech to output an indication of a health condition, such as a diagnosis of Alzheimer’s. In this case the LLM has been pre-trained, unsupervised, on large datasets to understand general context in the type of text data to be processed, before being fine-tuned on a classification task to map text (from speech) to one or more categories relating to a health condition prediction. This is a clear example of the application of an LLM to patient data, in the form of their speech, to provide a health condition prediction. The novel features of the training method and model can be shown to result in an improved health condition prediction, a problem that is considered “technical” and patent-eligible in the UK and Europe.
Example 2: Clinical assistants: Providing guidance to patients or clinicians
There are an increasing number of clinical assistants or “agents” that are being developed to provide advice and guidance directly to patient or clinicians. These chatbots are usually based on pre-trained LLMs that have been additionally trained on clinical data and question-answering tasks to facilitate a human-like interaction. In this case, if the problem being solved is related to the form of the output text, for example more accurate answers to clinical questions, then the problem solved may be considered administrative, based on improved text output, and not sufficiently limited to a specific technical domain.
There is also a distinction between this and example 1, despite both outputting information on diagnoses. In this second example the input data is not specific patient data but typed text data which draws it away from the EPO example of processing of patient data to provide a diagnosis. In this case, it is crucial to consider the best approach at the drafting stage. For example, do the novel features also provide improved methods of retrieving or processing data, or handling multi-modal training data, to provide the output? It may be that a different framing of the invention can assist in demonstrating the solution of a technical problem.
Conclusions
Despite widespread misconceptions, and the approach of the patent office still settling on these technologies, applications of LLM and other generative models may be protected by the patent system where they are applied to a technical problem. Often medical and health-related tasks are considered technical but an important distinction can be drawn between direct medical applications, such as automated diagnosis, and more administrative problems such as outputting a treatment plan. Even where these technologies are assessed as being patent eligible, a crucial second step that any IP adviser should take is to evaluate whether patent protection is the right option to leverage the greatest value of the innovation. It is essential for inventors to consider these issues carefully at an early stage to help them take the right decisions in protecting inventions incorporating these technologies.
If you would like to discuss patent protection in AI or Health Tech more generally, please email us: gje@gje.com.
Related resources
Patenting AI innovations in healthcare: navigating European patent law
Artificial intelligence (AI) is revolutionising the healthcare industry by enhancing our ability to accurately diagnose diseases and predict...
A cloud on the horizon: will the SaaS model work for medical AI tools under future regulations?
Technology and practices in the healthcare field are increasingly being augmented by AI. As the use of AI...

UKIPO revises AI patent guidelines after Emotional Perception ruling
The UKIPO has once again updated its patent examination guidelines for artificial intelligence (AI) inventions, representing a change...